
")
Hey data enthusiasts and curious minds! Ever heard of R and wondered what all the buzz is about? You know, that programming language that’s everywhere in the world of statistics and data science, making complex number-crunching look almost effortless? Well, get ready because we’re diving deep into the fascinating universe of R, uncovering some truly “R-rated” insights that the pros absolutely rave about. Even if you’re new to the game, don’t worry, we’ll keep it light, fun, and totally digestible!
Think of R as the unsung hero behind countless breakthroughs in fields like data mining, bioinformatics, and even social sciences. It’s not just a tool; it’s a vibrant ecosystem built by brilliant minds, constantly evolving, and powered by a passionate global community. While some of its deeper functionalities might seem a bit intimidating at first glance – a bit like those intense, critically acclaimed films that aren’t for everyone – mastering R can unlock incredible power for anyone looking to understand and visualize data in unprecedented ways.
In this super-sized listicle, we’re breaking down 15 essential things you need to know about the R programming language. We’ll explore its intriguing origins, its foundational strengths, and the amazing community that keeps it thriving and innovating year after year. Whether you’re a seasoned coder looking to deepen your expertise or just dipping your toes into the vast ocean of data, prepare to discover why R is such a formidable and beloved presence. Let’s kick things off with the very first steps of R’s incredible journey, straight from its core purpose!
1. What is R? The Powerhouse for Stats & Data Viz
So, let’s cut to the chase: what exactly *is* R? At its core, R is a programming language specifically designed for statistical computing and data visualization. Imagine a tool built from the ground up to handle numbers, crunch complex equations, and then present your findings in beautiful, insightful graphics that truly tell a story. That’s R in a nutshell, and it’s precisely why it has become an absolute staple for anyone serious about understanding and manipulating data.
This isn’t just a niche tool for academics anymore, though. The context clearly states that R “has been widely adopted in the fields of data mining, bioinformatics, data analysis, and data science.” This broad adoption speaks volumes about its incredible versatility and power across various high-stakes domains. From uncovering hidden patterns in vast healthcare datasets to modeling biological processes and informing critical business strategies, R is the go-to language for a multitude of impactful applications. It’s basically the ultimate Swiss Army knife for statistical heavy lifting, revered by experts globally!
Its ability to seamlessly integrate advanced statistical analysis with stunning, customizable visualizations is truly what sets it apart from many other programming environments. While other languages might require multiple, disjointed steps or external libraries to achieve similar compelling results, R often has these powerful capabilities built right into its core ecosystem or readily available through its expansive collection of specialized packages. If you want to not only understand your data but also tell a compelling, data-driven story with it, R provides the perfect, flexible canvas for your insights. It truly empowers users to transform raw numbers into meaningful, actionable intelligence.
2. The Brains Behind the Magic: Ross Ihaka & Robert Gentleman
Every great story has an origin, and R’s tale begins with two brilliant minds: professors Ross Ihaka and Robert Gentleman. These two visionaries, working together, started R back in August 1993 with a very specific, yet incredibly important, goal that would eventually blossom into something far greater than they might have initially imagined. Can you guess what this initial, foundational purpose was?
According to the context, R was initially created “as a programming language to teach introductory statistics at the University of Auckland.” How cool is that? What began as an educational tool, designed to simplify complex concepts for their students, evolved organically into one of the most powerful and widely used statistical software environments across the entire globe. It’s a remarkable testament to how practical, problem-solving approaches, even for seemingly modest academic needs, can lead to monumental innovations that impact entire industries.
Their foresight in developing a language specifically tailored for statistical education laid the crucial groundwork for R’s future success and widespread appeal. By focusing on the needs of learners and the clarity of statistical concepts, they inadvertently created a system that was not only robust enough for advanced, cutting-edge research but also accessible enough for newcomers to eventually dive in and thrive. Ross Ihaka and Robert Gentleman truly sparked a quiet revolution in statistical computing, and we’re all immensely benefiting from their incredible and lasting legacy today! Their collaboration brought us this amazing tool.

3. A Nod to the Past: R’s Influences from S and Scheme
So, R wasn’t magically conjured out of thin air, nor was it built in isolation! Like many profound innovations, it proudly stands on the shoulders of giants, drawing significant inspiration and foundational elements from other influential programming languages that came before it. Understanding these intellectual roots helps us truly appreciate the thoughtful and strategic design behind R’s powerful capabilities and its unique characteristics. It’s like tracing the fascinating family tree of a beloved pop culture icon, seeing where all the best traits came from!
Our context highlights two major and distinct influences that shaped R: the venerable S programming language and the elegant Scheme. The relationship with S is particularly intimate and foundational, with the document explicitly stating that “the language was inspired by the S programming language, with most S programs able to run unaltered in R.” This deep compatibility means R essentially picked up where S left off, building directly upon its robust statistical framework and extending its functionalities significantly. It’s truly like a spiritual successor, meticulously carrying forward the very best traits of its highly respected predecessor.
Furthermore, R also got a crucial intellectual boost from Scheme’s concept of “lexical scoping,” a programming concept that “allow[s] for local variables.” This might sound a tad technical, but in essence, it helps programmers manage variables within different, isolated parts of their code, making programs much more organized, predictable, and preventing unintended interference between different functions. These specific, well-considered design choices, intelligently inspired by established and respected languages, are an integral part of what makes R so incredibly powerful, reliable, and user-friendly for tackling even the most complex statistical tasks. It’s a perfect blend of proven concepts adapted for a new, dynamic era of data.
.png)
4. Why “R”? A Quick Peek into its Quirky Name
Have you ever wondered about the name “R”? It’s so short, so incredibly simple, yet it holds a couple of cool little secrets that give it a surprising depth! It’s not just a random letter plucked carelessly from the alphabet; there’s a charming and historically significant story behind it that connects directly to its humble origins and its brilliant creators. It’s almost like finding a clever, hidden easter egg in your absolute favorite movie – once you know, you can’t unsee it!
The context thoughtfully reveals the delightful double meaning behind the name “R,” giving us a glimpse into the minds of its founders: “The name of the language, R, comes from being both an S language successor and the shared first letter of the authors, Ross and Robert.” How incredibly clever and perfectly concise is that? It’s a subtle yet powerful nod to its direct inspiration, the S language, acknowledging its heritage, and simultaneously serves as a personal touch from its co-originators, Ross Ihaka and Robert Gentleman. It’s a name that is concise, immensely memorable, and deeply steeped in a rich, meaningful history.
This elegant naming convention isn’t merely a fun piece of trivia; it profoundly symbolizes the continuity of ideas and the personal investment that went into creating and nurturing R from its nascent stages. It’s a clear testament to how closely tied the language is, not only to its esteemed predecessors but also to the pioneering vision and dedication of its brilliant creators. So, the next time you confidently type ‘R’ into your console, take a moment to remember that you’re connecting with a powerful legacy that is both technically profound and surprisingly personal, a true hallmark of innovation!
Read more about: 11 Cars So Problematic, Owners Are Seriously Wishing for an ‘Insurance Event’ (If You Catch Our Drift)

5. The Open-Source Advantage: Free and Flexible for All
One of the absolute best things about the R programming language, and an incredibly huge reason for its widespread and rapid adoption across countless industries, is that it’s completely free and available as open-source software! In a modern world where high-quality, professional tools often come with hefty, prohibitive price tags, R boldly stands out as a shining champion of accessibility and equality. This isn’t just a minor, convenient detail; it is, in fact, a fundamental and deeply ingrained aspect of its very identity and enduring success.
The context explicitly states, with no room for ambiguity, that “R is free and open-source software distributed under the GNU General Public License.” What does this powerful statement truly mean for you, the aspiring data scientist or seasoned analyst? It means you are completely free to download it, use it for any purpose, modify its code to suit your specific needs, and even distribute your own enhanced versions without ever paying a single cent. This open and collaborative model profoundly fosters relentless innovation, boundless collaboration, and crucially ensures that R remains readily available to absolutely everyone, from individual students learning their first lines of code to massive, multinational corporations tackling petabytes of data. It’s a true, global democratization of incredibly powerful statistical computing.
This deeply ingrained open-source ethos has actively cultivated and continuously sustains a vibrant, self-propelling community where countless developers and enthusiastic users from all corners of the world wholeheartedly contribute to its constant growth and refinement. Because of this, pesky bugs get identified and fixed with remarkable speed, innovative new features are constantly added to its toolkit, and an immense wealth of collective knowledge is generously shared freely among its members. It’s truly like an endless, collaborative hackathon, perpetually improving, endlessly adapting, and always pushing the boundaries of what’s possible. This unwavering commitment to openness is an absolutely critical ingredient in R’s ongoing popularity and its enduring, powerful appeal to the global data science community.
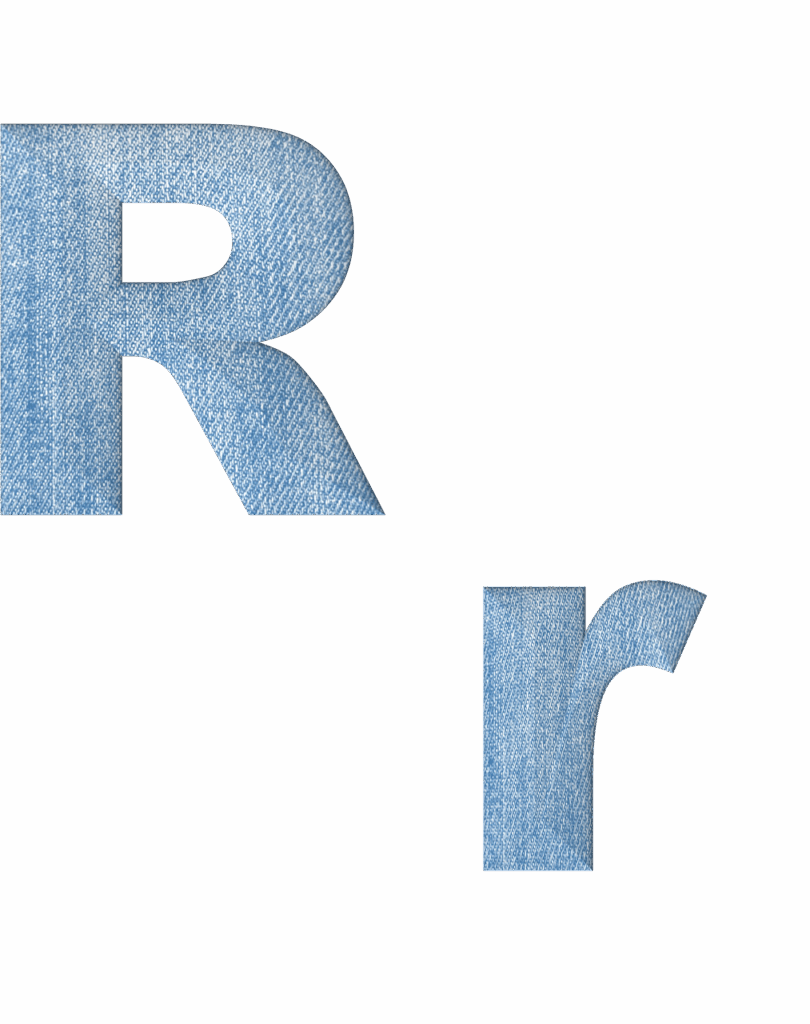
6. Beyond the Basics: How R’s Packages Supercharge Functionality
If the core R language is the powerful, reliable engine of a high-performance vehicle, then its vast ecosystem of packages are undeniably like the specialized tools, cutting-edge upgrades, and custom paint jobs that instantly transform a standard car into an unrivaled, high-performance racing machine! These incredible packages are an absolute game-changer, dramatically expanding R’s capabilities far beyond its foundational functions and truly making it a versatile powerhouse. They are, without a doubt, where R’s immense power and adaptability truly explode into action!
As the context vividly explains, “R packages are collections of functions, documentation, and data that expand R.” Think of them as expertly pre-written modules of code that you can effortlessly plug and play directly into your R environment whenever you need them. These aren’t just minor, convenient additions; they are substantial enhancements that can add “reporting features (using packages such as RMarkdown, Quarto, knitr, and Sweave) and support for various statistical techniques (such as linear, generalized linear and nonlinear modeling, classical statistical tests, spatial analysis, time-series analysis, and clustering).” That’s an almost unimaginable amount of extra horsepower and specialized functionality at your fingertips!
The sheer volume, breathtaking variety, and remarkable quality of these readily available packages are nothing short of staggering, making R an incredibly adaptable solution to almost any conceivable statistical or intricate data analysis challenge you might encounter. This unparalleled ease of package installation and subsequent use is explicitly highlighted as a major factor that “contributed to the language’s adoption in data science.” It fundamentally means you rarely, if ever, have to painstakingly reinvent the wheel for every new task; chances are, someone in the incredibly active and generous R community has already meticulously built a robust, tested package specifically designed to help you out. It’s truly like having an entire army of highly skilled coding assistants at your beck and call, ready to tackle anything!

7. Tidy Up Your Data: Diving into the Tidyverse Collection
Alright, we just talked about how R packages are undeniably awesome, and now it’s absolutely time to introduce one of the absolute rockstar collections of packages that has revolutionized data analysis: the tidyverse! If you’re looking to make your data analysis workflow cleaner, significantly more efficient, and frankly, much more enjoyable and intuitive, then the tidyverse is unequivocally your new best friend. It’s like equipping yourself with the ultimate, perfectly organized toolkit for data wrangling superheroes, ready to conquer any messy dataset!
The context thoughtfully describes the tidyverse as an “example… which bundles several subsidiary packages to provide a common API.” This collection isn’t just a random, haphazard assortment of tools; it’s a meticulously curated set of packages explicitly designed to work together seamlessly, following a consistent and elegant philosophy. This invaluable common interface means that once you master how to use one tidyverse package, you’ll find it exponentially easier to pick up and effectively utilize all the others, creating an incredibly smooth, logical, and intuitive data analysis workflow from start to finish.
The tidyverse powerfully “specializes in tasks related to accessing and processing ‘tidy data’,” a concept which the context precisely defines as “data contained in a two-dimensional table with a single row for each observation and a single column for each variable.” This groundbreaking concept of “tidy data” is nothing short of revolutionary, fundamentally making data manipulation much more straightforward, predictable, and significantly less prone to frustrating errors. With iconic packages like `ggplot2` for creating breathtaking visualizations, `dplyr` for incredibly efficient data manipulation, and `readr` for streamlined data import, the tidyverse truly enhances functionality for “visualizing, transforming, and modelling data, as well as improves the ease of programming (according to the authors and users).” It’s absolutely no wonder that data scientists, from beginners to veterans, universally adore it for its clarity and power!
Alright, data explorers, are you ready to dig even deeper into the R universe? We’ve only just scratched the surface of what makes this language a total game-changer for anyone working with data. From its foundational principles to its incredible community and cutting-edge features, R is constantly evolving, making complex tasks feel effortlessly achievable. So, let’s power through the remaining aspects that truly showcase R’s advanced capabilities and the passionate network that sustains it!

8. The Global Hub: CRAN and its Vast Repository
If R’s packages are the specialized tools for your data science toolkit, then the Comprehensive R Archive Network, or CRAN, is absolutely your ultimate, go-to app store for all things R! Founded way back in 1997 by Kurt Hornik and Friedrich Leisch, CRAN isn’t just a place to download software; it’s the central, meticulously organized repository that hosts R’s source code, all those ready-to-run executable files, crucial documentation, and, most importantly, the incredible wealth of user-created packages that make R so powerful and adaptable. It’s truly the lifeblood of the R ecosystem, keeping everything neatly organized and readily accessible to everyone.
Just imagine starting with only three mirror sites and a modest twelve contributed packages. Fast forward to today, and CRAN has exploded into a global phenomenon! As of June 30, 2025, it boasts an astonishing 90 mirrors worldwide and an incredible 22,390 contributed packages. This phenomenal growth isn’t just a statistic; it represents a thriving, constantly expanding community that is continuously innovating and generously sharing its work. This incredible scale underscores CRAN’s pivotal role in R’s success, making cutting-edge tools and methodologies available at your fingertips, literally anywhere in the world.
But wait, there’s more! CRAN goes beyond just hosting files; its “Task Views” area is a super helpful guide, listing packages specifically relevant for niche topics. Whether you’re into causal inference, high-performance computing, machine learning, medical imaging, social sciences, or spatial statistics, there’s a curated list to point you in the right direction. Plus, R isn’t just tied to CRAN; packages are also available in other cool spots like R-Forge, Omegahat, and GitHub, not to mention the specialized Bioconductor project which provides packages tailored for genomic data analysis and high-throughput sequencing methods. Talk about options!
9. A Thriving Community: The R Core Team, Foundation, and Consortium
Behind every great programming language, there’s an even greater community, and R is no exception! This isn’t just a solitary open-source project; it’s a vibrant, interconnected network of brilliant minds and passionate users who are constantly pushing the boundaries of what R can do. It’s a true testament to collaboration, showing how collective effort can build and sustain something truly extraordinary. Let’s meet the main groups that are the backbone of R’s continuous evolution.
First up, we have the legendary R Core Team, which was officially founded in 1997 with the crucial mission of maintaining the R source code itself. These are the folks ensuring the language stays robust, stable, and cutting-edge. Then, to provide much-needed financial muscle, the R Foundation for Statistical Computing stepped in, established in April 2003. Think of them as the champions who ensure R has the resources to thrive. And don’t forget the R Consortium, a fantastic Linux Foundation project dedicated to developing and strengthening R’s underlying infrastructure. Together, these three groups form a powerful triumvirate, ensuring R remains at the forefront of statistical computing.
Beyond these core groups, the R community is a lively hub of knowledge sharing and collaboration. The R Journal, for example, is an open-access academic journal that’s a treasure trove of information, featuring everything from short articles on new packages and programming tips to crucial CRAN and Foundation news. It’s a fantastic resource for staying informed and deepening your R expertise, offering insights directly from the developers and power users themselves. This collaborative spirit is truly what makes the R ecosystem so dynamic and inviting for learners and experts alike.

10. Gathering of Minds: R’s Vibrant Conference Scene
For a programming language built on collaboration, it’s no surprise that R has an incredibly vibrant scene for connecting with fellow enthusiasts! Forget those stuffy academic gatherings; R conferences are buzzing hubs where data scientists, statisticians, and developers come together to learn, share, and celebrate all things R. It’s truly a place where you can geek out over new packages, swap coding tips, and make connections that last a lifetime, all while soaking in the latest trends and innovations.
One of the absolute highlights is UseR!, the annual international R user conference. It’s like the Super Bowl for R enthusiasts, bringing together thousands from around the globe for intense learning sessions, inspiring keynotes, and plenty of networking opportunities. But that’s not all; there’s also the Directions in Statistical Computing (DSC) conference, offering another fantastic platform for diving deep into the computational aspects of statistics and data analysis. These events are crucial for fostering a sense of community and driving innovation forward.
And the R community truly champions inclusivity! We have amazing groups like R-Ladies, an organization dedicated to promoting gender diversity within the R community by providing support, mentorship, and opportunities for women and gender minorities. Then there are SatRdays, brilliant R-focused conferences thoughtfully held on Saturdays, making them accessible to a wider audience. Plus, R is frequently a star player at broader Data Science & AI Conferences, and the renowned posit::conf (formerly rstudio::conf) is a must-attend for anyone serious about R and its powerful tools. And for those quick updates and community vibes, just follow #rstats on social media—you’ll be amazed at the constant flow of awesome content!

11. Elegant Structure: R’s Object-Oriented Programming (S3 and S4)
Ready to talk about how R manages to be so flexible and powerful behind the scenes? It’s all thanks to its native support for object-oriented programming (OOP)! This isn’t just fancy jargon; it’s a fundamental design choice that allows R to handle complex data structures and operations with incredible elegance and efficiency. R basically gives you two distinct, native frameworks to play with: the S3 and S4 systems, each with its own unique flavor for organizing and interacting with data.
Let’s start with S3, which is often described as the more informal of the two. With S3, objects are assigned to a class simply by setting a “class” attribute. This system primarily supports “single dispatch on the first argument,” meaning that when you call a generic function like `summary()`, R looks at the class of the first argument to decide which specific method to execute. For example, if you pass a numeric vector to `summary()`, it gives you descriptive statistics, but if you pass a factor (like `as.factor(data)` from our context), it gives you a table of counts for each level. It’s incredibly intuitive and flexible, letting you easily extend existing functions to work with your own custom data types.
Then there’s the S4 system, which is a bit more formal and rigorous. It’s designed more like the Common Lisp Object System (CLOS), featuring formal classes and generic methods. This powerhouse supports both “multiple dispatch” (meaning R considers the classes of *all* relevant arguments, not just the first, when deciding which method to use) and “multiple inheritance” (allowing a class to inherit features from several parent classes). While S3 is great for quick, informal extensions, S4 provides a more structured and robust framework for building complex, enterprise-level applications where strict method definitions and class hierarchies are crucial. It’s like having two different gears for different levels of complexity!

12. Streamlining Code: The Native Pipe Operator and Assignment
Now, let’s talk about the nitty-gritty of writing R code, because getting your syntax right is key to unlocking all that data-crunching magic! In R, you’ll quickly notice that the generally preferred way to assign values to variables isn’t just the `=` sign, but a super cool arrow made from two characters: `<-`. While `=` *can* be used in some cases, the arrow `<-` is the idiomatic R way, and it’s a visual cue that data is flowing into your variable. It’s all about making your code clear and easy to read, right?
Beyond simple assignments, R shines in its ability to handle various data structures with ease. You can create numeric vectors with a simple `x <- 1:6`, then effortlessly perform element-wise calculations like `y <- x^2` or `z <- x + y`. Need to transform your data into a matrix? No problem! `z_matrix <- matrix(z, nrow = 3)` gets the job done, and you can even transpose and manipulate it with `2 * t(z_matrix) – 2`. And when it comes to structured data, `data.frame` objects allow you to organize information into named columns, making access incredibly intuitive using `$Z` or `[‘Z’]`. R just makes data wrangling feel like a breeze!
And for a truly game-changing feature that arrived with R version 4.1.0, get ready for the native pipe operator, `|> `! This brilliant little symbol lets you chain functions together, transforming your data step-by-step in a super readable flow, rather than getting lost in a maze of nested function calls. Instead of `nrow(subset(mtcars, cyl == 4))`, you can write `mtcars |> subset(cyl == 4) |> nrow()`, which is much easier to follow, right? Even influential R programmers like Hadley Wickham suggest using this powerful operator, just keep your chains to about 10-15 lines to maintain clarity and avoid what he calls “code obfuscation.” It’s all about writing code that’s both powerful and pristine!

13. Beyond the Console: R’s Powerful Interfaces and IDEs
While R happily starts you off with a command-line interface (CLI) – perfect for those who love typing commands directly – the truth is, there’s a whole world of fantastic tools out there to make interacting with R even more seamless and visually appealing! Think of it as having your choice of dashboards for your high-performance data machine. These diverse interfaces are a huge reason why R is so incredibly approachable and user-friendly for people with all sorts of coding preferences, from keyboard warriors to drag-and-drop enthusiasts.
For many, the go-to choice is an Integrated Development Environment, or IDE, and RStudio is arguably the reigning champion! It bundles everything you need—a console, code editor, plot viewer, and more—into one slick package. But it’s not the only player in town; you’ve got R.app (for macOS users), Rattle GUI, R Commander, RKWard, Positron, and Tinn-R, offering a rich variety of environments. Plus, R even plays nicely with general-purpose IDEs like Eclipse (via the StatET plugin) and Visual Studio (with R Tools), so you can stick with your comfort zone if you already have one!
If you prefer a more minimalist approach, R integrates beautifully with popular source-code editors like Emacs (especially with the ESS package) and Vim (thanks to the Nvim-R plugin). Other great options include Kate, LyX (using Sweave for literate programming), WinEdt, and the incredibly popular Jupyter notebooks for an interactive, cell-based coding experience. And get this: R isn’t a solo act! It integrates smoothly with other scripting languages like Python, Perl, Ruby, F#, and Julia, as well as general-purpose languages like Java and C# via things like the Rserve socket server. R truly speaks a universal language of data!

14. Visualizing Insights: R’s Built-in Modeling and Plotting Prowess
Okay, so we’ve established R is a statistical powerhouse and a data-wrangling wizard. But what about making all those numbers *sing*? That’s where R’s incredible built-in support for data modeling and graphics comes in! It’s not enough to just find insights; you need to effectively communicate them, and R provides all the tools you need to create stunning visualizations that tell a compelling data story. It’s like having a top-tier design studio right inside your code editor, ready to bring your data to life with just a few lines of script.
Imagine this: you’ve got some data, `x` and `y`, and you want to see if there’s a linear relationship. With R, it’s as simple as `model <- lm(y ~ x)`. Just like that, you’ve created a linear regression model! But R doesn’t stop there. Calling `summary(model)` gives you an in-depth statistical breakdown of your model, with all the juicy details like coefficients, standard errors, t-values, and p-values. And for a visual diagnosis of your model’s performance, `plot(model)` can generate a suite of diagnostic plots, even allowing mathematical notation in labels to keep things super professional. How cool is that for quickly assessing your statistical work?
And R’s graphical capabilities stretch far beyond standard statistical plots! Remember that captivating Mandelbrot set visualization? That wasn’t just a pretty picture; it highlighted R’s robust ability to handle complex numbers and perform intricate calculations for advanced graphical output. Using packages like `caTools` and functions like `write.gif`, R can render breathtaking visualizations, pushing the boundaries of what you might expect from a “statistical” language. From basic histograms to animated fractals, R gives you the power to see your data in truly imaginative and insightful ways.
15. A Touch of Whimsy: The Peanuts-Themed Version Names
Who doesn’t love a fun little Easter egg, especially in something as powerful as a programming language? Well, R has one of the coolest and most enduring traditions around: its version releases have delightful, pop culture-infused codenames! Forget boring numerical increments; all R version releases from 2.14.0 onward boast whimsical codenames that make direct reference to the iconic Peanuts comics and films. It’s a truly charming touch that adds a bit of personality and humor to every update, making the R community feel a little more like a friendly neighborhood!
This unique naming system actually drew inspiration from other open-source projects, notably the Debian and Ubuntu Linux distributions, which also use playful codenames for their releases. And there’s a fantastic, self-deprecating reason behind the Peanuts theme, too! According to core R developer Peter Dalgaard, it stems from the humorous observation that “everyone in statistics is a P-nut.” How’s that for an inside joke that brings a smile to your face? It truly shows the lighthearted spirit thriving within the often-serious world of data science.
So, the next time you update your R installation, keep an eye out for these fantastic names! You might be downloading a version called “Great Square Root” (R 4.5.1), “How About a Twenty-Six” (R 4.5.0), or perhaps you’re still rocking “Puppy Cup” (R 4.4.0) or even “Arbor Day” (R 4.0.0). These quirky titles aren’t just for fun; they’re a subtle nod to the language’s rich history, its connection to a beloved cultural touchstone, and the playful personalities of the brilliant minds who continue to make R such an incredible and enduring tool. It’s truly a legacy that’s both powerful and delightfully charming!
And there you have it, data aficionados! Fifteen deep dives into the incredible R programming language, from its humble origins and open-source spirit to its global community, versatile packages, and surprisingly whimsical version names. R isn’t just a tool; it’s a dynamic, ever-evolving ecosystem that empowers users to transform raw data into stunning insights. Whether you’re a seasoned expert or just starting your data journey, R offers a universe of possibilities that are as engaging as they are impactful. So go forth, explore, and let R help you tell your data’s unique story!


